Create a traditional to simplified chinese converter using Python
Introduction
Simplified and Traditional Chinese are the standard characters of the Chinese Language. As named, simplified Chinese is the reduced (usually fewer strokes) version as compared to its more complicated cousin(usually more strokes) Traditional Chinese. I will show you an easy way to convert traditional Chinese text to Simplified Chinese.
Preparation
The first thing we need is a mapping table of traditional chinese to simplified chinese. I have gotten one from tutormandarin.net website. So do some webscrapping and transformation, I came up with this csv file
Importing the libraries
The main library we will need is the csv. Depending on if you want to convert a webpage, you can add the urllib as well.
import csv
import urllibRead CSV and store it to dictionary
We will need to store all the mapping tables in the program. I decided to use dictionary to save it as it allows quick access and there are only 900+ entries so it will not be resource intensive. We will need to open the file with the right encoding for this to work. There are a lot of ways to figure out the encoding such as opening it in text editors like sublime text or visual studio code. Another way is via Python which I showed at the bottom of this post. Then read the csv into a list and form it as a dictionary.
f=open('traditional_simplified.csv', encoding="gbk")
reader=csv.reader(f, delimiter=',')
d={row[1]:row[0] for row in reader}Read the file to be converted
I have included two versions, one for the local file and one for a webpage. Same as the csv, we will need to add the right encoding if not the program will crash.
# local file version
old_file=open('a.htm',encoding="utf-8")
# webpage version
oldfile = urllib.request.urlopen('https://tw.yahoo.com').read()
old_file=oldfile.decode('utf_8')Create the output file
We will need to create a new file to store the output indicating the encoding and write permission. The encoding should be the same as the file that is to be converted.
new_file=open('b.htm','w', encoding="utf-8")Actual replacement
Here is the fun part. What we will do is line by line, character by character do a replace using the dictionary. We will keep this replace in a try except because of a character not present as the dictionary key will cause keyerror so we will ‘pass’ to the next character. After completing all the characters in the line, we will write the newly converted line with simplified characters to the new file before we move to the next line and do everything all over again. After completing all the lines, close the new file. Don’t worry. The program does not take long to run, I have tested on the tw.yahoo.com website, and it took 2 seconds!
for line in old_file:
for character in line:
try:
line=line.replace(character, d[character])
print(character + " found and replaced with" + d[character] + "!")
except:
pass
new_file.write(line)
new_file.close()Summary
So there you have it, a traditional Chinese to Simplified Chinese converter in just 15 lines of code. You can even change it to a simplified to traditional converter by inverting the dictionary items and keys or swapping the columns of the CSV file! Full code is as below.
# Local file version
import csv
f=open('traditional_simplified.csv', encoding="gbk")
reader=csv.reader(f, delimiter=',')
d={row[1]:row[0] for row in reader}
new_file=open('b.htm','w', encoding="utf-8")
old_file=open('a.htm',encoding="utf-8")
for line in old_file:
for character in line:
try:
line=line.replace(character, d[character])
print(character + " found and replaced with" + d[character] + "!")
except:
pass
new_file.write(line)
new_file.close()
# Webpage version
import csv
import urllib
f=open('traditional_simplified.csv', encoding="gbk")
reader=csv.reader(f, delimiter=',')
d={row[1]:row[0] for row in reader}
new_file=open('b.htm','w', encoding="utf-8")
oldfile = urllib.request.urlopen('https://tw.yahoo.com').read()
old_file=oldfile.decode('utf_8')
for line in old_file:
for character in line:
try:
line=line.replace(character, d[character])
print(character + " found and replaced with" + d[character] + "!")
except:
pass
new_file.write(line)
new_file.close()Bonus: Check your file for encoding type
Checking your file for the type of encoding used is simple. All you need to do is to read the file as bytes then attempt to decode it with an encoding. If it is the wrong encoding, it will trigger a UnicodeDecodeError error. So all we need to do is to try to decode with all the possible encoding types until we hit a bingo. I have already gathered all possible encoding that can support Chinese characters so we will need to loop through each one until we get the correct encoding.
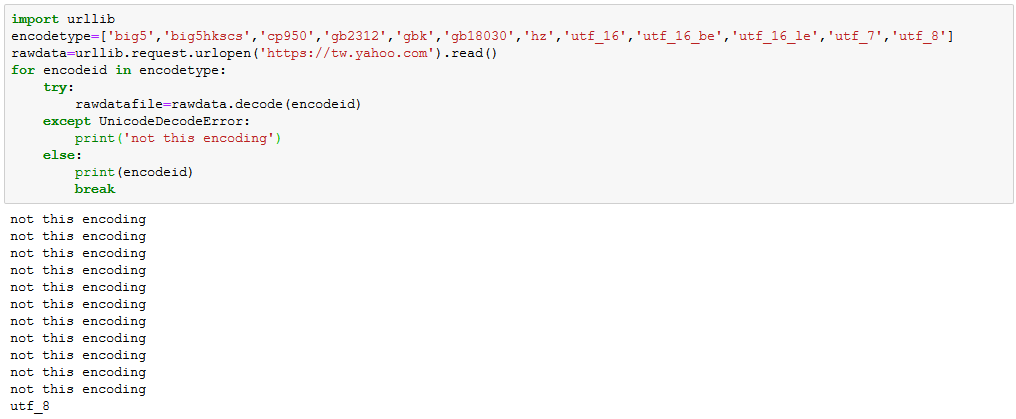
#local file version
encodetype=['big5','big5hkscs','cp950','gb2312','gbk','gb18030','hz','utf_16','utf_16_be','utf_16_le','utf_7','utf_8']
rawdata = open('traditional_simplified.csv','rb').read()
for encodeid in encodetype:
try:
rawdatafile=rawdata.decode(encodeid)
except UnicodeDecodeError:
print('not this encoding')
else:
print(encodeid)
break
#url version
import urllib
encodetype=['big5','big5hkscs','cp950','gb2312','gbk','gb18030','hz','utf_16','utf_16_be','utf_16_le','utf_7','utf_8']
rawdata=urllib.request.urlopen('https://tw.yahoo.com').read()
for encodeid in encodetype:
try:
rawdatafile=rawdata.decode(encodeid)
except UnicodeDecodeError:
print('not this encoding')
else:
print(encodeid)
break
