Create a treeview using excel and Python
Introduction
Exel or other spreadsheet programs, for all its prowess to do mathematically related tasks(e.g., budgeting, statistics) is at its most primitive form, a list. So, one of the prevalent use cases of Excel is to store information(and I mean literally like a to-do list, contact list or even knowledge base). This post will show an easy way using python to convert this:
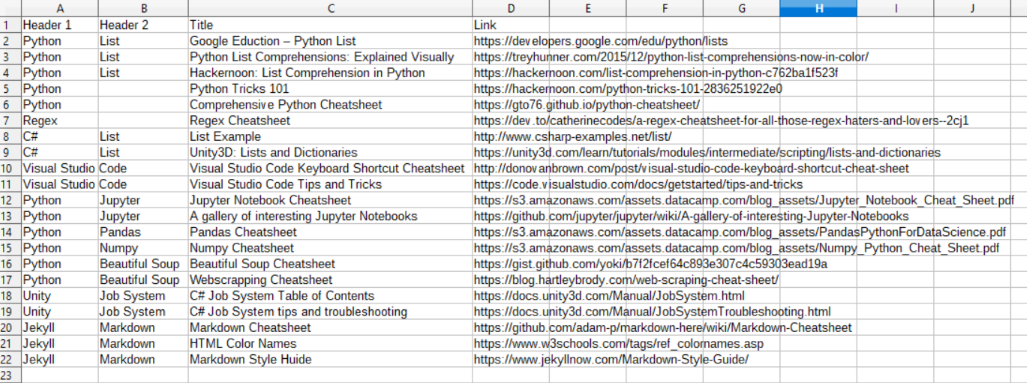 to this:
to this:
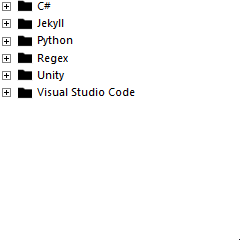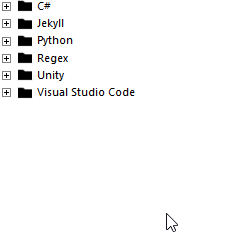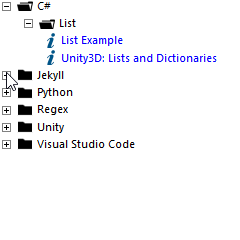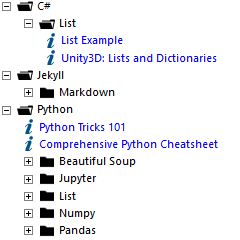
Preparation
The result below is an HTML file with the tree view feature created via CSS. I have created(well literally copying, noob at html/css) this template by modifying on what Martin Ivanov has created.
The python part is to generate the html file. One of the main reasons I decided to use Martin Ivanov’s CSS Treeview is because of the ease in creating the HTML code necessary to generate the treeview which suits my purpose.
The other reason is that there is no javascript involved so this is usable in a corporate environment where there might blocking of javascript content.
What is needed in the HTML
Martin has documented the process of writing the HTML. But to be honest, he has done a terrific job in keeping it minimalistic to the point we can probably figure out just by looking at his example.
Basically what is needed is any parent tree/subtree will need to be supplied as a list item(li)with a label and checkbox, this will then wrap around its children subtree/item with a unordered list(ul).
Same thing is repeated for the children if it is a subtree(it will be supplied with a label and checkbox etc, etc).
When we finally reach the actual item, we will just set it up as a list item.(I decorated it with a hyperlink as my example is a list of hyperlinks)
Getting the data
We need the pandas library for this, using the read_excel method to read the excel file. As I am expecting empty header fields, I used fillna to set blank values as a string called @Null$tring. We will then catch for @Null$tring in the program to determine if there is no need for a header.
Lastly I will sort the values based on ‘Header 1’ and ‘Header 2’(yours could be different header name based on your excel). This is mandatory, THE WORLD WILL END IF YOU DO NOT DO THIS!!! (Well, you will not get the right output as it is dependent on sequential order to generate the correct HTML content)
import pandas
df1=pandas.read_excel('selfhelp.xlsm').fillna("@Null$tring").sort_values(by=['Header 1', 'Header 2'])Storing the data
We will using 4 lists to store the data. One for each of the two header, 1 for the title and lastly for the link. We will creating 1 variables to store the content which we will write to a HTML file later.
headers1 = list(df1.loc[:,"Header 1"])
headers2 = list(df1.loc[:,"Header 2"])
titles = list(df1.loc[:,"Title"])
links = list(df1.loc[:,"Link"])
messageList=[]Boilerplate HTML Code
First part is to add some boilerplate HTML code to the list, these are the stuff which contains the header and what CSS file to look for and division element which acts as an container to get the CSS configuration required.
Most of the code from Martin Ivanov’s example.
messageList.extend(['<!DOCTYPE html>','<html lang=\"en\">','<head>','<meta charset=\"UTF-8\">','<title>\"Excel to Treeview using Python\"</title>','<link rel=Stylesheet type=\"text/css\" media=all href=\"treeview.css\">','</head>','<body>','<div class=\"css-treeview\">','<ul>'])Forming the parent tree and subtree
Now we can loop through the individual item to form the treeview starting with the headers. Note that rather than looping through each item, I chose to loop through the index instead as this allows me to check the next/previous item in the list.
for i in range(len(headers1)):We will first check for the ‘@Null$tring’ to determine if there is a need to create a header.
Next, we will check the previous item allows determining if we need to form a new header if the current item is different from the previous. But first, We will need to ensure we are checking from the second item onwards as the first item will not have any prior item to check against.
Thanks to the use of logical operators, the comparison will be short-circuited(if the first comparison fails, it will not move to the next one) so we can merge the three comparisons in a single line.
if headers1[i] != '@Null$tring' and (i==0 or headers1[i] != headers1[i-1]):Then we will populate the HTML string with the field in the boilerplate code. Do the same checking of the previous item with header2 and populate the HTML code to get the below.
for i in range(len(headers1)):
if headers1[i] != '@Null$tring' and (i==0 or headers1[i] != headers1[i-1]):
messageList.append('<li><input type=\"checkbox\" /><label>%s</label><ul>' % (headers1[i]))
if headers2[i] != "@Null$tring" and (i== 0 or headers2[i] != headers2[i-1]):
messageList.append('<li><input type=\"checkbox\"/><label>%s</label><ul>' % (headers2[i]))Forming the item
Next is to populate the HTML code for the actual item.
messageList.append('<li><a href=\"%s\" target="_blank">%s</a></li>' % (links[i], titles[i]))Closing the unsorted list and list tag
Last up we will check the next item’s header against the current one. But first, We will need to ensure we are checking up to second last item if not we will end up with the infamous index out of range error as we are comparing to next item and the last item will not have any next item.
if i+1!=len(headers1):If the next item’s header and the current are different, we will close the ul to allow the creation of the new header in the next loop. We will also check if the current item’s header is of @Null$tring. If it is, we can skip the closing. Do the same for the second header.
if i+1!=len(headers1):
if headers1[i+1]!=headers1[i]:
messageList.append('</ul></li>')
if headers2[i]!='@Null$tring':
messageList.append('</ul></li>')
elif headers2[i+1] != headers2[i] and headers2[i]!='@Null$tring':
messageList.append('</ul></li>')Finale
Now all we have to do is to add in the trailing HTML boilerplate and write the list to a html file.
messageList.append('</ul></div></body></html>')
f = open('output.html', 'w')
for msg in messageList:
f.write(msg)
f.write("\n")
f.close()Summary
The full code is available below. You can also check out the output and source I created for reference here.
import pandas
df1=pandas.read_excel('selfhelp.xlsm').fillna("@Null$tring").sort_values(by=['Header 1', 'Header 2'])
headers1 = list(df1.loc[:,"Header 1"])
headers2 = list(df1.loc[:,"Header 2"])
titles = list(df1.loc[:,"Title"])
links = list(df1.loc[:,"Link"])
messageList=[]
messageList.extend(['<!DOCTYPE html>','<html lang=\"en\">','<head>','<meta charset=\"UTF-8\">','<title>\"Excel to Treeview using Python\"</title>','<link rel=Stylesheet type=\"text/css\" media=all href=\"treeview.css\">','</head>','<body>','<div class=\"css-treeview\">','<ul>'])
for i in range(len(headers1)):
if headers1[i] != '@Null$tring' and (i==0 or headers1[i] != headers1[i-1]):
messageList.append('<li><input type=\"checkbox\" /><label>%s</label><ul>' % (headers1[i]))
if headers2[i] != "@Null$tring" and (i== 0 or headers2[i] != headers2[i-1]):
messageList.append('<li><input type=\"checkbox\"/><label>%s</label><ul>' % (headers2[i]))
messageList.append('<li><a href=\"%s\" target="_blank">%s</a></li>' % (links[i], titles[i]))
if i+1!=len(headers1):
if headers1[i+1]!=headers1[i]:
messageList.append('</ul></li>')
if headers2[i]!='@Null$tring':
messageList.append('</ul></li>')
elif headers2[i+1] != headers2[i] and headers2[i]!='@Null$tring':
messageList.append('</ul></li>')
messageList.append('</ul></div></body></html>')
f = open('output.html', 'w')
for msg in messageList:
f.write(msg)
f.write("\n")
f.close()
